
Dimodelo Shift Architecture
Extract, Land and Load
Dimodelo Shift is responsible for extracting data from a source, landing it in the appropriate intermediate store (like a Data Lake) and loading it into the Transient Staging layer, ready for consumption by the Persistent Staging layer.
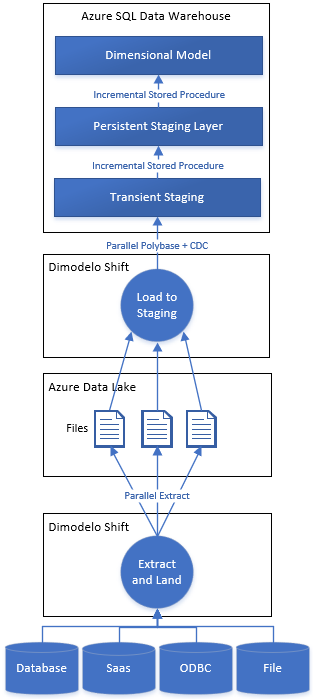
Extract and Land
Extract Step
Table/View or Query
The Extract process is different depending on which pattern you choose.
If you have defined a table or view as the source. Dimodelo Shift will generate a query to select data from the source entity. The query will be modified depending on the pattern you selected. If you specify a query, Dimodelo Shift will generate a query that wraps your specified query as a subquery. If you used a CTE(s) Dimodelo Shift will correctly reformat your the query to use the specified CTE(s). In addition, in both cases, Dimodelo will apply any mapping expressions you have specified on the mapping tab.
The queries are modified according to the chosen pattern in the following ways:
- Full Extract. The generated query extracts all the data in the table/view/query.
- Incremental Pattern. Extracts only the data that has been added or updated since the last time the extract ran for this source. E.g. you can use this pattern to extract only transactions from a large transaction table that have been inserted or updated since the last time the extract was executed. The incremental pattern is more efficient than the Full Extract pattern. For the pattern to work, you need to specify a column or multiple columns that the source table uses to track change, like a modified date or sequence number. These are known as the change identifier column(s). During the execution of the persistent staging stored procedure, Dimodelo saves the maximum value of the change identifier column(s) present in the Persistent staging table at the end of the Load process. The values are saved to the zdm.ControlParameters table in the Warehouse database. When Dimodelo Shift generates the Extract query, it first selects the change identifier values from zdm.ControlParameters and then injects these values into a WHERE clause to only select data where the change identifier(s) are greater than the selected value.
- Date Range Pattern. The date range pattern is used to extract a subset of the source data based on a date range. The end of the date range is the current batch execution date. The start of the date range is a number of days specified prior to the current batch effective date. All data within the date range is extracted, regardless of whether it has changed since the last time the extract ran. The query is modified with an injected WHERE clause filtering the results based on the identified Date Range Date column in the source and the calculated start and end of the date range.
- Change Tracking Pattern. The change tracking pattern uses the change tracking feature of SQL Server to identify changes (insert, update, delete) in a source database and extract only the data that changed since the last time the extract ran. It only supports SQL Server table sources (not queries or views). To use the change tracking pattern, it’s necessary to turn change tracking on for the source SQL Server table. Change Tracking works in a similar way to the Incremental pattern. It saves the maximum change tracking version number for the table to the zdm.ControlParameters table after the persistent staging table is successfully updated. Dimodelo Shift first selects the change tracking version number value from zdm.ControlParameters, then it modifies the extract query to join to the CHANGETABLE supplying the selected version number.
Multi Wild Card File
Multi Wild Card File Pattern. This pattern is specific to files. The developer defines a file name pattern (with wild cards), and Dimodelo Data Warehouse Studio will extract the data from all files, that match that naming pattern, into the staging table. Dimodelo Data Warehouse Studio will also manage the files, archiving them in an archive folder. In this case, Dimodelo Shift does not generate a query, instead, it connects to the file and extracts the data directly. It is possible to map columns from the source schema to the target schema, and to map to parameters using the @parameterName syntax. If there is only one source file then the read side of the extract is sequential (It’s not possible to have a multi-thread read a single file). This can impact performance,(although Dimodelo Shift is optimised to read files as quickly as possible). The pattern will perform better if there are multiple source files. Dimodelo Shift will read multiple source files in parallel improving overall throughput.
Buffer Step
Each row from the source is transformed into the target schema and reconstructed into a new row for the target file. This occurs in-memory. It is important to understand that Dimodelo is reformatting the data suitable for ETL downstream processes. The row is formatted with the correct text qualifiers, field delimiters etc.
Aggregate Step
The new Rows are aggregated into an in-memory file. The file size is determined by the file size setting for the Extract. Once the file size is reached, the in-memory file is passed off to a Lander process, for transfer to the Azure Destination. Dimodelo Shift then opens a new In-Memory file if there are more rows to be Extracted. In this way, Dimodelo Shift can be reading and buffering data into an in-memory file while simultaneously transferring another file to the destination (i.e. Data Lake, Azure SQL Database, Azure SQL Server.
Lander Step
There are different Landers depending on the destination.
Azure Data Lake
The Azure Data Lake Lander is passed an in-memory file by the Aggregator, once the Aggregator reaches the file size limit. The file represents a file that needs to be loaded into the data lake. Using the metadata of the solution, the Lander determines the data lake file path of the new file. The new file is suffixed by the row number of the first row in the file. The lander then begins to stream the file to the Data Lake. If the file needs to be compressed, the file is compressed by Dimodelo Shift during the streaming process. The lander can stream more than 1 file at the same time. If the Aggregator is passing the Lander files faster than it can stream them, then it may be streaming multiple files at the same time.
Azure SQL Database/SQL Server
The Azure SQL Database Lander is passed an in-memory file by the Aggregator, once the Aggregator reaches the file size limit. The file represents one of the potentially many files that need to be loaded into the temporary table (temp. schema not #temp table) in Azure SQL Database/SQL Server. Using the metadata of the solution, the Lander determines the temporary table name. It creates the file if it doesn’t exist, and will drop and create it if it already exists the first time the Lander tries to write to it during the current batch. The Lander then use SQL Bulk copy to load the data into the temporary table. The lander can bulk copy load more than one file at the same time and Bulk Copy on the SQL Server side accommodates parallel bulk loading into a single table. If the Aggregator is passing the Lander files faster than it can load them, then the Lander may be loading multiple files at the same time.
Load to Staging
Azure Synapse Analytics
If the target technology is Azure Synapse Analytics, Dimodelo generates a Create Table As (CTAS) SQL statement selecting data from the “Latest” folder of the target entity in the Data Lake and writing it to a temporary table (temp. schema not #temp table). The temp table is created with the same distribution as the target persistent staging table. Dimodelo follows Microsoft’s recommended best practice for Synapse. Prior to executing the CTAS, Dimodelo generates a FILE FORMAT and EXTERNAL TABLE statement to create the necessary prerequisite for reading data from the Data Lake in the correct format. These are dropped and created each time the ETL runs to ensure the schema and file format are correct.
The CTAS instigates a Polybase process to read data in parallel from the Azure Data Lake. Polybase is powerful because it runs in parallel on each Synapse distributed node.
Some things to note.
- If a file is not compressed, then Polybase can run multiple reader threads to a single file.
- If a file is compressed, then Polybase can run only a single reader thread against each file. This means, to get parallel reads with compressed files, its necessary to have multiple files. This has implications for the file size settings of an Extract.
Azure SQL Database/SQL Server
For Azure SQL Database and SQL Server, the Load to Staging is achieved by the bulk copy performed by the Lander.
Change Data Capture
In some cases, it’s necessary for Dimodelo Shift to determine what has changed.
When the Extract pattern is “Full Extract” or “Date Range” Dimodelo needs to compare the data in the temp. table with the data in the persistent staging table to determine what changed (insert/update/delete). To do this Dimodelo Shift generates a CTAS query that does a full outer join between the temp. table and the persistent table (psg. ) and compares matched records on a checksum. The result set includes all rows that have been inserted, updated or deleted. The result set is wrapped in the CTAS, which creates a new “temp.delta” table which contains just the changed rows. The temp.deleta table then replaces the original temp. table.
With the other patterns (Incremental, File, Change Tracking) this step is not necessary, as the temp. table already contains just the changeset. This is another reason incremental patterns are much faster, as the CDC compare step is costly.
At the end of the CDC process the temp. table, in all cases, represents the changeset. When the Persistent Staging process runs its source is guaranteed to only be the changeset subset of rows and is able to assimilate the changes quickly and easily. Persistent Staging is not executed by Dimodelo Shift. Persistent Staging is managed through stand-alone stored procedures that are executed after the Extract phase of the workflow.
Note: the Multi-File Extract pattern assumes that the files represent a changeset of data. I.e. new payroll files. A file can contain a row that was loaded from a previous file in a previous run. Based on the business key, the persistent staging process will just treat that row as changed, and record a new version of the row. It’s important to understand that reloading the same file more than once creates new versions of all the rows in the persistent staging table. This isn’t a problem perse, as Dimodelo is designed to manage versions. However, if you are constantly loading the same file, or a “Full Extract” file (i.e. the same file, with the same data, plus some changes), then it would be more sensible to use an ODBC driver connection to the file and use the “Full Extract” Pattern. Dimodelo would then apply the Change Data Capture process and only update persistent staging with what changed.
Performance
Factors affecting performance
- You can run multiple Dimodelo Shift Extract processes at the same time. That is multiple Extracts, each for a different Staging Entity at the same time. The default is 4 entities. Dimodelo is not particularly memory or CPU intensive, so as long as the server that Shift runs on is sufficiently resourced, then running multiple extracts at the same time improves overall throughput. Note, this is in addition to the parallelism that Dimoldeo Shift is achieving for each Extract (discussed above).
- Network constraints will negatively affect the load time. A single extract can burst up to 500Mb/sec. If you have limited connectivity to Azure, then the network will be the constraining factor. In this case, we recommend using the default compression setting for Extracts. This will achieve a 50%-70% compression and reduce the network requirement. In addition, Incremental Extracts will mean you are sending less data across the network.
- For large files, the best throughput is obtained by increasing the file size. 512MB is recommended. If the network is not a constraining factor we also recommend not compressing the files.
- Polybase. If files are compressed, then there need to be multiple files for Polybase to work in parallel. This needs to be taken into account when choosing file size and compression settings for an Extract. The recommended minimum file size is 128MB, which is the Dimodelo Shift’s default.